I’ve often needed to read and aggregate large amounts of NDJSON records stored in AWS S3 and while I can do that efficiently in TypeScript or spin up a spark job to process the data, finding a neat solution in R has proved challenging. After finding a solution I am happy with I thought I’d share it, especially because I found the documentation quite challenging to understand to the point I needed to go look at the source code of the packages involved.
Data used in this example is from Kaggle and is 5 years of reddit moderator actions in the r/conspiracy sub-reddit.
I started by spinning up Minio, an S3 compatible object store that I can run locally to quickly develop my solution against. They have good install guides for all platforms in their documentation, I downloaded their Linux .deb package and ran the server using the following command to get a server running with a username and password with storage setup in a folder off my home drive called minio:
1
2
# set environment variables the root username and password and then run the minio serverMINIO_ROOT_USER=admin MINIO_ROOT_PASSWORD=MY_ROOT_PASSWORD minio server ~/Documents/data/minio --console-address ":9001"
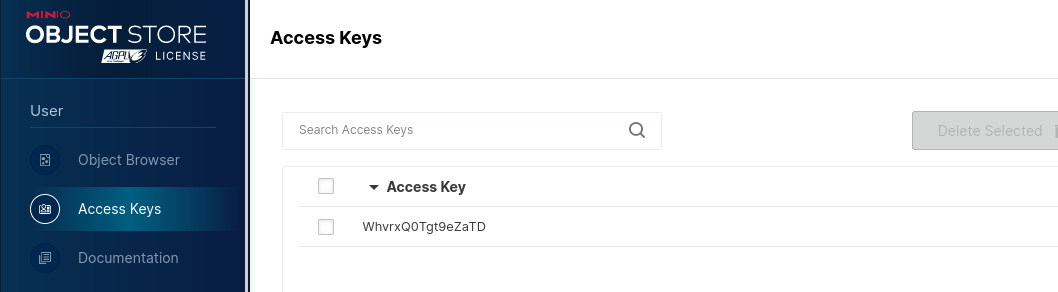
Once I had minio running I opened the admin console in my browser at http://localhost:9001 and created an access key after choosing the “Access Keys” menu on the left under User.
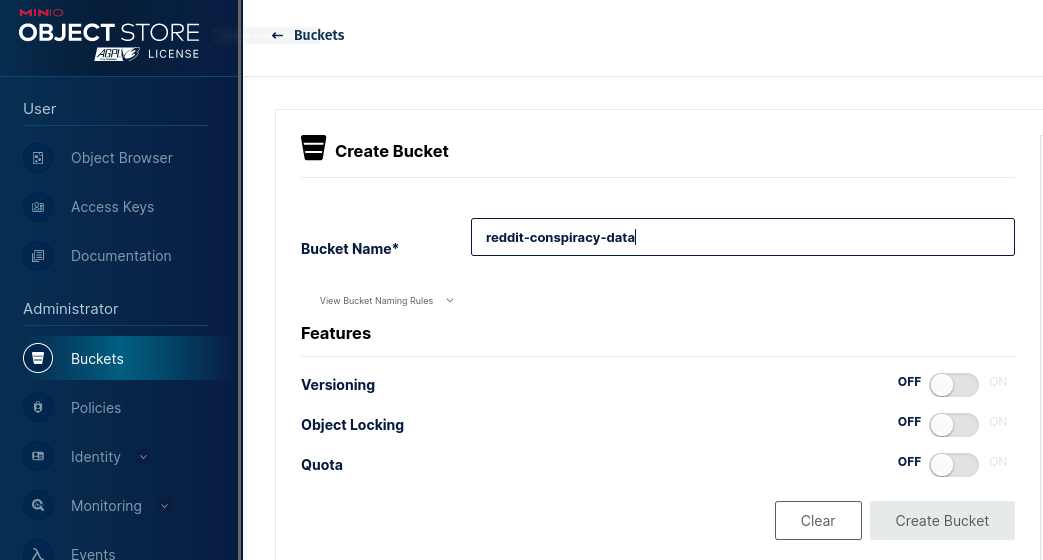
I then created a bucket by choosing the “Buckets” menu on the left under Administrator.
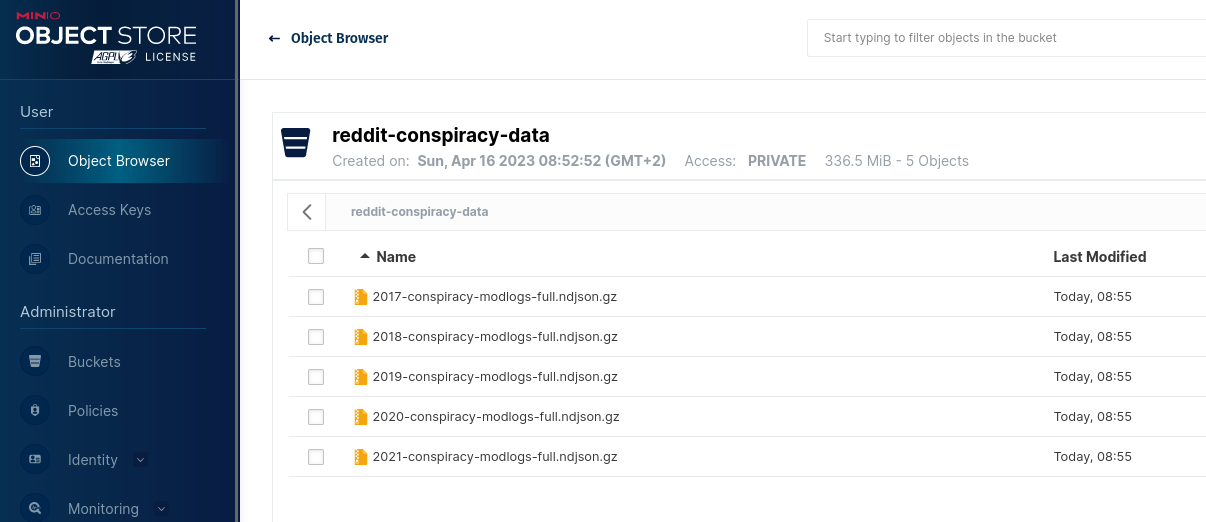
I downloaded the r-conspiracy data from the link above and gzipped the files as they range from 100MB to almost 800MB uncompressed. I then opened the bucket in the Minio object browser by choosing “Object Browser” on the left menu under user and finally I dragged the compressed files into the bucket ending up with the result below.
Now we have some locally hosted source data to learn with, I fired up R-Studio and created the R script to read and process the data from the bucket, the final version can be found in this github repo.
Listing the files to be processed
I used the aws.s3 R package to interact with the data.
The basics were quite simple, using the get_bucket function to retrieve the contents of the bucket we just created. The only complexity was getting the AWS client to use the local endpoint from my minio server rather than the real AWS endpoint. I had to set the AWS_S3_ENDPOINT environment variable AND set the aws region to an empty string and disable HTTPS for each function I used, but this is only an issue if you are using a local S3 bucket and not much of an inconvenience.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
library(aws.s3)# set environment variables for AWS S3 connection, these could be set exeternallySys.setenv("AWS_ACCESS_KEY_ID"="YOUR_ACCES_KEY_FROM_MINIO","AWS_SECRET_ACCESS_KEY"="YOUR_SECRET_KEY_FROM_MINIO","AWS_DEFAULT_REGION"="us-east-1",# change this to your AWS S3 region if it's not us-east-1# leave this off if you aren't using minio as your s3 storage locally"AWS_S3_ENDPOINT"="127.0.0.1:9000")# the name of the s3 bucketitem_bucket<-"reddit-conspiracy-data"# list the files in the bucketyearly_conspiracy_files<-get_bucket(item_bucket,# these extra arguments are not required if you are not using minio locallyuse_https=FALSE,region="")
Parsing the compressed data and extracting the JSON data
This part proved to be a lot more complex, I’ve used the ndjson R package extensively in the past and it handles gzipped versions too, but I didn’t want to have to create local files manually for each discovered file in S3. After some digging in the aws.s3 codebase I found the s3read_using function that lets you specify how you want to handle the file retrieved from S3 using your own function.
In the code below I added a function that s3read_using can use to parse the data from S3 and return a data table using the ndjson package’s stream_in function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# processModerationFile## function to process each gzipped ndjson file of reddit moderations# returns the parsed ndjson data as a data table# processModerationFile<-function(path_to_S3_data_item){print(path_to_S3_data_item)moderations<-stream_in(path_to_S3_data_item,c('dt'))moderations}# read the S3 data for this s3 object and pass the data to the specified function (processModerationFile)mod_data<-s3read_using(FUN=processModerationFile,object=s3_full_path,# you can leave these "opts" out if you are not using minio as your local S3 storageopts=c(use_https=FALSE,region=""))
Summarising r-conspiracy actions from gzipped NDJSON data
Putting it all together the code below shows setting the required environment variables, a function to parse the NDJSON data, a function to summarise the data for each year and then the main code that lists the files in the bucket and loops over them and calls the two functions above ending up with a single set of summarised data that you can visualise as needed.
library(aws.s3)library(ndjson)library(foreach)library(tidyverse)# set environment variables for AWS S3 connection, these could be set exeternallySys.setenv("AWS_ACCESS_KEY_ID"="YOUR_ACCES_KEY","AWS_SECRET_ACCESS_KEY"="YOUR_SECRET_KEY","AWS_DEFAULT_REGION"="us-east-1",# change this to your AWS S3 region if it's not us-east-1# leave this off if you aren't using minio as your s3 storage locally"AWS_S3_ENDPOINT"="127.0.0.1:9000")# processModerationFile## function to process each gzipped ndjson file of reddit moderations# returns the parsed ndjson data as a data table# processModerationFile<-function(path_to_S3_data_item){print(path_to_S3_data_item)moderations<-stream_in(path_to_S3_data_item,c('dt'))moderations}# processModerationYear## function to process the reddit moderations for a year# returns a summary of the moderations for that year#processModerationYear<-function(moderations,file_year){moderations%>%mutate (year=file_year)%>%group_by(year,action,mod)%>%summarise(num_actions=n())}# the name of the s3 bucketitem_bucket<-"reddit-conspiracy-data"# list the files in the bucketyearly_conspiracy_files<-get_bucket(item_bucket,use_https=FALSE,region="")# loop over the files in the bucket and row bind the results of each loop iterationmoderation_summary<-foreach(j=1:length(yearly_conspiracy_files),.combine=rbind)%do%{# get the s3 item for this iterations3_item=yearly_conspiracy_files[[j]]# construct a full path for the items3_full_path=stringr::str_interp("s3://${s3_item$Bucket}/${s3_item$Key}")# extract the year from the first 4 characters of the file namefile_year=stringr::str_sub(s3_item$Key,1,4)# read the S3 data for this s3 object and pass the data to the specified function (processModerationFile)mod_data<-s3read_using(FUN=processModerationFile,object=s3_full_path,# you can leave these "opts" out if you are not using minio as your local S3 storageopts=c(use_https=FALSE,region=""))# process the received data, summarise and returnprocessModerationYear(mod_data,file_year)}
Hopefully this will be useful to someone else accessing AWS S3 from R, there are a few tricks to learn but it’s fairly straight forward once you have figured them out.